2008-05-10
JIT on Tamarin Tracing
前回のつづき. 今日は JIT を眺めてみます.
そのまえに少し補足. TT のコードはまだ登場したばかりで, じゃんじゃん書き変わっている. なのでここで書いている内容は早々古くなってしまう.
どんな勢いで書き変わっているかというと, たとえば前回紹介した TT Forth の "SUPER:" は もうすぐ撤廃される. (該当bug.) かわりに fc.py が命令列の長さから半自動的に superword を生成するようになる. ついでに Interpreter.cpp に書かれていた IL プリミティブの実装 C++ コードが vm.fs のインラインに埋め込まれるようになる. (semantic aciton みたいなもんですね.)
そんなわけなので, あとから照合して「全然違うじゃん!」と怒らないようにしてください > いつかぐぐってやってくる方々.
Tracing Tree
で, 本題. TT の使う JIT, Tracing Tree アルゴリズムは, "Incremental Dynamic Code Generation with Trace Trees (PDF)" という記事で詳しく解説されている. Tracing Tree にはおおよそ三つの特徴がある:
- 制御構造を CFG(control flow graph) = DAG ではなく, ツリー構造であらわす. (basic block を繋ぐ辺が合流しない.)
- 関数ではなくループをコンパイルの単位とする
- 能動的に命令列を解析するのではなく, VM の評価ループから呼ばれるフックでツリー構造などをつくる
アルゴリズムだけを説明しても先の記事の焼き直しになってしまうので, 実装を覗きつつ話を進めたい.
JIT 結果のコード(IL/LIR/x86)は TC 同様 -Dverbose で見ることができます.
loopdge(): JIT のためのフック
三つめの特徴にあるように, JIT 関係のコードは VM の評価ループにこそっと埋めこまれている. 具体的には分岐命令をフックする. これは二つめの特徴, ループを中心とした JIT に関係している. 実行中にループを検出するため, JIT は "前方向へのジャンプ" をループの終点をみなす. ジャンプ先をループの先頭だと仮定するわけ.
...
loop:
var i = 0;
do_something();
++i;
if(i < 10) { goto loop; } // ここでフックする.
...
具体的なフックの呼び出しこんなかんじ:
// Interpreter.cpp
// bool --
// branch if false, 4byte offset
PRIM(void, LBRF)(Interpreter& interp, Frame*& f, wcodep& ip, Boxp& sp, wcodepp& rp)
{
//ip = ip + (a ? 4 : *((int32_t*)ip));
int32_t j = readUnalignedInt32(ip);
sp--;
if (!sp[1].i)
{
ip += j;
if (j < 0) // ジャンプ幅のオフセットが負 = 前方向なら ....
{
...
LOOPEDGE(interp); // フックを呼び出す
}
}
....
}
IL の命令である LBRF にフックが埋め込まれているのがわかる. ほかに 条件が正ならジャンプする LBRT 命令と, 関数呼び出しの ENTERABC 命令, 関数から抜ける EXITABC 命令にフックがある. 関数まわりは再起呼び出しの場合のみフックを呼ぶ.
LOOPEDGE() マクロはこんなの.
#include "nanojit.h"
#define LOOPEDGE(i) do {\
InterpState state(ip,sp,rp,f);\
TIMING_START(t_taken)\
(i).loopedge(state);\
TIMING_END(t_taken)\
f=state.f; ip=state.ip; sp=state.sp; rp=state.rp;\
} while (0)
loopedge() メソッドがフックの実体だ. いくつかの例外を除き, JIT 関係の処理は この loopedge() を起点にする. 関数呼び出し/呼びだされを起点にする典型的な JIT とはだいぶ違いそうなのがわかる.
Fragment: Tracing Tree のデータ構造
loopedge() を見てみよう.
void Interpreter::loopedge(InterpState &state)
{
if (!allowTracing)
return;
Fragment* frag = frago->getLoop(state);
...
冒頭で "Fragment" というオブジェクトを取得している. "frago" 変数は Fragment オブジェクトのコンテナである Fragmento のインスタンス. (このクラス名はどうよ...) Fragmento::getLoop() は必要に応じて Fragment のインスタンスを作成する.
Fragment* Fragmento::getLoop(const avmplus::InterpState &is)
{
Fragment* f = _frags->get(is.ip);
if (!f) {
f = newFrag(is);
_frags->put(is.ip, f);
....
}
return f;
}
この Fragment (o なし)オブジェクトがコンパイラでいう basic block にあたる. InerpState::ip は VM の instruction pointer. つまり Fragmento コンテナは命令の先頭位置をキーに Fragment を保存している. 定義を抜粋しておこう:
/**
* Fragments are linear sequences of native code that have a single entry
* point at the start of the fragment and may have one or more exit points
*
* It may turn out that that this arrangement causes too much traffic
* between d and i-caches and that we need to carve up the structure differently.
*/
class Fragment
{
public:
....
DWB(Fragment*) branches; // ツリーの子
DWB(Fragment*) nextbranch; // ツリーの兄弟
DWB(Fragment*) anchor; // ツリーのルート
DWB(LirBuffer*) lirbuf; // LIR 出力
....
private:
NIns* _code; // ptr to start of code (ネイティブコード)
GuardRecord* _links; // code which is linked (or pending to be) to this fragment
// コード生成時に考慮すべき "ガード" のリスト (後述)
int32_t _hits; // パスの通過回数 (後述)
LInsp _map; // serialized state of the stacks packed in LIR buffer
};
ツリー構造になっているのと, JIT ぽいあれこれがあるなーという理解で十分. あとでまた出てきます.
loopedage() は分岐命令からのフックだったのを思いだそう. Tracing Tree では, このように VM の実行に応じて basic block ならぬ Fragment のデータ構造を構築していく. だから通らないパスのコードが JIT されることはない.
loopedage() に戻ってつづき. (基本的にこのメソッドが tracing tree のほとんど全てです):
void Interpreter::loopedge(InterpState &state)
{
...
Fragment* frag = frago->getLoop(state);
if (tracing())
{
...// 最初はこっちを通らないので省略
}
if (!frag->code()) // JIT された native code がなければ...
{
// この Fragment を通過した回数を数えて,
if (++frag->hits() > HOTLOOP) { // そのカウントが閾値を越えたら...
sot(frag,state); // "tracing" を開始する: "Start Of Trace"
}
}
else
...
}
このように, loopedge() では実行パスの通過回数を Fragment オブジェクトに記録しておく. で, 回数が所定の量を越えると JIT を行う. 頻度に応じた JIT の仕組みが少しずつ見えてきた, かも.
"trace" するとは具体的に何をするのだろう. まず sot() を見てみる:
void Interpreter::sot(Fragment *tracefrag, InterpState &interp)
{
...
set_tracing(true); // 開始フラグをたてた!
this->tracefrag = tracefrag; // trace 対象の Fragment を保存
...
NanoAssert(!tracefrag->code()); // まだ JIT 前なのを確認
...
// LIR 命令を出力する LirWriter を用意
LirBuffer *lirbuf = new (core->gc) LCompressedBuffer(frago);
LirWriter *lirout = lirbuf->writer();
...
}
LirWriter をセットアップしている. TT での "tracing" とは, native コードの手前の低レベル表現である LIR の生成を指している. 元ネタである Tracing Tree の tracing は制御構造の追跡全般を指している. ちょっと紛らわしい.
class Interpreter
{
....
inline void set_tracing(bool t) { m_nottracing = t ? 0x00 : 0xff; }
set_tracing() では m_nottracing をセットする.
ここからしばらくいやらしい C のコードがつづくけど我慢してください.
まずこんなマクロがあって...
#define NEXTIP (*ip++ & m_nottracing)
評価ループの先頭にこんなコードがある...
void Interpreter::inner(Frame *f, wcodep ip, Box *sp, wcodepp rp)
{
top_of_loop:
INTERP_PRE
switch (NEXTIP)
{
... ここで命令の解釈
}
tracing 中はいつも NEXTIP がゼロになるのに注目.
値がゼロの命令は...
// vm.fs
...
// TRACE must come first (and have a value, even if bogus) because it must be op 0
{ TRACE (( -- )) 0 }
うへ. なんつう bogus だよ. TRACE の実装をみると...
#define INTERP_TRACE(x) TIMING_END(t_interp) } goto handle_trace;
はいはい...
// Interpreter::inner()
handle_trace:
....
if (superpos)
{
... // super word 用の workaround.
// superword を構成する個々の word を trace しなおす
}
else
{
...
trace(f, ip-1, sp, rp);
...
switch (curword)
{
... // 評価ループの該当ラベルに goto. 実際の命令が実行される.
}
...
}
はいはい...
void Interpreter::trace(Frame* f, const wcodep ip, const Boxp sp, const wcodepp rp)
{
...
const Token curword = ip[-1];
...
trace2(f, ip, sp, rp);
...
}
...というわけで無事いやらし圏を突破. tracing 中は命令毎に trace2() メソッドが呼ばれ, そのあと命令本体が動くのがわかった.
trace2() は, いま動かしている IL に対応した LIR を生成する:
void Interpreter::trace2(Frame* f, const wcodep ip, const Boxp sp, const wcodepp rp)
{
LirWriter *lirout = tracefrag->lirbuf->writer();
....
// このへんで定数伝搬などの局所最適化を行う
....
switch (*ip) // 現在実行している命令について...
{
.....
case CHOOSE:
{
// 対応する LIR を発行!
LIns* i0 = uselo(sp);
LIns* i1 = uselo(sp-1);
LIns* i2 = uselo(sp-2);
// sp[-2] = sp[0] ? sp[-2] : sp[-1]
i = lirout->ins_choose(i0, i2, i1, assm->has_cmov);
varset(sp-2, i);
break;
}
.....
}
}
他にも細かな高速化が色々ちりばめられているので, 興味のあるひとは覗くと面白いかもしれない. とにかく, TT における tracinig は LIR の生成というネイティブコードの準備フェーズだということが わかった.
このまま LIR を生成し続けると, あっという間にメモリが溢れてしまう. 適当に打ち切る必要がある. 打ち切りには eof() メソッド (end of tracing) を使う.
void Interpreter::eot(InterpState &state, Fragment *target)
{
TIMING_START(t_eot)
set_tracing(false); // tracing フラグを戻す.
...
if (assm->error())
...
else
{
// if we are currently tracing let's terminate it and then join the fragments
guard(lastop, /*cond*/NULL, state, target);
if (assm->error())
...
else
{
//
// JIT の瞬間! LIR をネイティブコードに変換する.
// assm は nanojit モジュールの Assembler オブジェクト.
//
compile(strk.location, rtrk.location, assm, tracefrag);
...
}
}
verbose_only( if (core->config.verbose_trace) verbose = assm->_verbose = false;)
TIMING_END(t_eot);
}
こうして tracing 中に作られた LIR は無事ネイティブコードになった. 万歳! LIR -> native の変換は特に新味もないので省略. 先に進みます.
eot() メソッドはエラー時に呼ばれるほか, 先に登場した分岐フックの loopedge() からも呼ばれている.
void Interpreter::loopedge(InterpState &state)
{
if (!allowTracing)
return;
Fragment* frag = frago->getLoop(state);
if (tracing()) // tracing 中なら...
{
...
eot(state, frag); // tracing を終える
// might have just flushed, re-get frag
frag = frago->getLoop(state);
}
... // 下の抜粋につづく...
}
JIT で作られたネイティブコードはいつ動かすのかというと, このあとすぐに呼ばれる.
// Interpreter::loopedge() つづき
...
if (!frag->code())
{
...// JIT されたコードがない場合. (既出.)
}
else
{
callfrag:
...
// calling to generated arm code, use normal address
union { NIns *code; GuardRecord* (FASTCALL *func)(InterpState*,Fragment*); } u;
u.code = frag->code();
lr = (*u.func)(&state, 0);
...
TIMING_END(t_frag)
currentFrame = state.f;
...
}
...
frag->code() が JIT の作ったネイティブコードを返し, それを呼び出している. あるループで LIR を生成したら, その次のループからナイティブコードになるわけね. あたりまえの話だけれど, 同じコード(パス) の trace/JIT は基本的に一度だけ. ネイティブコードは Fragment::_code に保存されており, 次回以降の loopedge() ではすぐにそれが呼び出される.
...これで TT JIT の大まかな流れがわかった.
ただし大筋以外にも解決すべき問題は色々あり, コードにはそのための仕掛けが用意されている. このあとは, その仕掛けから面白そうなものをいくつか紹介する.
ガード
上で説明した Tracing JIT は, インタプリタの実行したパスしかコンパイルしない. だから, たとえば
function foo(n:int) : int {
var i:int = 0;
for (i = 0; i<n; ++i) {
if (100 == i) {
for (var j:int; j<10; ++j) {
i = i+j; // 特に意味はありません...
}
return i;
}
}
return i;
}
...
var x:int = foo(10);
みたいなコードを動かすと, "100 = i" のパスは実行されず, コンパイルもされない. その後の呼び出しで "100 = i" のパスに入ると, ネイティブコードは中断してインタプリタに戻る. イメージとしてはこんなコードにコンパイルされる.
void generated_foo(interpreter_t* interp) {
int n = interp->args[0];
int i = 0;
for (i = 0; i<n; ++i) {
if (100 == i) {
goto side_exit_at_path_1:
}
}
interp->result = i;
return;
side_exit_at_path_1:
interp->state = the_state_at_the_path;
return;
}
この <ネイティブコードを中断してインタプリタに戻る> 仕組みをガード (guard), 中断する位置を side exit という. TT の JIT はガードを多用する.
コンパイラづくりは分岐で basic block を区切るのがお約束になっている. TT JIT はガードを使うことで, "前に戻る" ジャンプまでが一区切りのコードブロックになる. その間には(先に進む)分岐を含むことがある. 先に Fragment は basic block に相当すると書いたけれど, うけもつコード片は分岐をふくむぶん長くなる.
状態の復元
伝統的な関数単位の JIT は, バイトコード上の関数とネイティブの関数が 1-1 で対応していた. おかげでインタプリタからネイティブコードへの呼び出しも割と素朴に実装することができた. (see TC.)
TT はループ単位で JIT を行うため, バイトコードの関数と生成されるネイティブコードが 1-1 で対応しない. そのせいでネイティブコードをバイトコードの関数の途中で呼び出したり, ネイティブコードから戻る場所がバイトコードの関数の中間だったりする. 戻る側は特に厄介だ. 戻った箇所から整合性を保って VM のインタプリタを再開するには, インタプリタの状態を適当に復元する必要がある.
たとえば以下のような AS のコードがあったとして...
function bar(n:int) : int {
var i:int = 0;
for (i:int = 0; i<10; ++i) {
if (5 == bar()) {
break;
}
}
//after_loop:
i += 10;
return i;
}
この for 文のブロックだけが JIT されたとする. (Tracing JIT では典型的な場面.) JIT で作られたネイティブコードから戻ったあと, インタプリタは after_loop とコメントのある行から動作を開始し, VM のローカル変数 i にも適当な値が入っていなければいけない. これはガードのパスで特に問題になる.
TT JIT は, ネイティブ関数の引数としてインタプリタの状態をまとめた InterpState 構造体を引き渡す. JIT はここに状態を書き戻すコードを生成し, 整合性の問題を扱う. (詳しくは Assembler::nFragExit() など参照.) めんどい.
パッチ
さて, ガードではハズレのパスに入るとインタプリタに戻ると書いた. これは少し悲しい. 初回にたまたま頻度の低いパスを選んでしまったら, ループの中でいつもインタプリタに戻る羽目になる.
Tracing Tree の木構造を考えてみよう. この場合, 通常の(外側の)ループを含む foo のパスが親ノード. i=100 のパスの(内側の)ループが子ノードとなる.
TT JIT は子ノードを別の Fragment としてコンパイルする. 親も子もイティブコードを持つとき, 一旦インタプリタに戻るのは無駄足だ. TT JIT は後からコードを書き直し, ガード時のジャンプ先を子ノードに変更する. この仕組みを patch と呼ぶ.
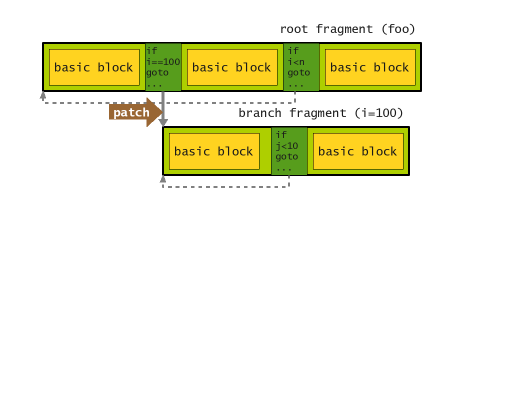
コードをみてみよう. まずネイティブコードから戻ったところから. ネイティブコードの戻り値 lr は GuardRecord 型のオブジェクト. インタプリタ再開のための追加情報が含まれている.
void Interpreter::loopedge(InterpState &state)
{
lr = (*u.func)(&state, 0); // ネイティブコード実行
...
if ((frag = lr->target) == 0) // 復帰先の Fragment が指定されていない
{
if (...) {
frag = frago->getMerge(lr, state); // 既存のパスを探すか
} else {
....
frag = frago->createBranch(lr, state); // 新しく作る
....
}
....
// writing to the lr here requires dcache/icache sync
lr->target = frag;
if (frag->code()) { // コードがあった場合の処理
assm->patch(lr); // ネイティブコードの戻りパスを子の Fragment に繋ぐ
goto callfrag;
} else {
frag->addRecord(lr); // この復帰先にジャンプしてくるパスとして,
// 元のネイティブコードからの戻り位置を記録する
// コード生成の際にはパスをつなぐ
}
....
}
....
}
中断情報を元に, 子(ジャンプ先)の Fragment で patch しているのがわかる.
コード生成時に patch() をすることもある:
// Assembler.cpp
void Assembler::assemble(Fragment* frag)
{
// とりあえず普通にコード生成
...
_epilogue = genEpilogue(SavedRegs);
...
NIns* loopJump = gen(frag->lirbuf->reader()); // perform single pass
...
NIns* patchEntry = genPrologue(SavedRegs);
...
if (!error()) // エラーでないなら
{
....
frag->fragEntry = patchEntry;
frag->setCode(_nIns);
// patch other frags to this new one now.
GuardRecord *lr = frag->links();
while (lr)
{
GuardRecord *next = lr->next;
NanoAssert(lr->target == _thisfrag);
patch(lr); // 先に登録しておいたジャンプ元が
// 生成したコードにジャンプするよう変更
lr = next;
}
}
...
}
こうした地道な工夫がガードのペナルティを減らしている. ちなみに patch() の実装は CPU 毎に異り, i386 だとこんなの:
// Nativei386.cpp
void Assembler::patch(GuardRecord *lr)
{
Fragment *frag = lr->target;
NIns *save = _nIns;
verbose_only(verbose_outputf("patching jump at %X to here", lr->jmp);)
_nIns = lr->jmp +5; // +5 is size of JMP
JMP_long_nochk(frag->fragEntry);
_nIns = save;
}
メソッド呼び出し
JIT の単位がループだと, メソッド呼び出しの変換は面倒が多そうだ. なにしろこのままだと関数の冒頭は JIT されない. 一旦インタプリタに戻ればいいが, 性能を考えると都合が悪い.
メソッド呼び出しは, Forth では enterenv 命令としてこう記述されている:
// caller will NEST to get here, EXECUTE is an indirect jump (tail jump),
// so the impl code's EXIT will return directly back to caller
: enterenv ( obj args argc -- result )
ckint RSTKREM 0<= IF stkover THEN ENV getforthimpl EXECUTE ;
(本当はこの前後にフレームの push/pop があるけれど, 本筋とは関係ないので省略.)
getforthimpl は C++ の関数で, forth 命令列へのポインタを返す. IL の INVOKEI 命令を通じて呼び出される.
wcodep FASTCALL getforthimpl(MethodEnv* env)
{
return env->getForthWord();
}
EXECUTE は C++ で実装された IL プリミティブ. getforthimpl がスタックに積んだ命令列で, 現在の instruction pointer を上書きする.
PRIM(void, EXECUTE)(wcodep& ip, const wcodep newip)
{
AvmAssert(newip != 0);
ip = newip;
}
こうした IL レベルの操作を, どう LIR にマップすればいいのだろう. trace2() を見てみよう.
case FINVOKEI:
case IINVOKEI:
case QINVOKEI:
{
lirout->ins(arg1op, useq_or_lo(arg1op, sp));
i = lirout->insCall(ip[1]);
varset(sp,i);
break;
}
getforthimpl を呼び出すための IINVOKEI 命令は, LIR の call 命令に置き換えられる. 意外性はないものの, IL のポインタがあってもネイティブコードはどうしようもない...
EXECUTE はこんなの:
case EXECUTE:
guardConstant(sp,state);
break;
ガードがあるだけ. 仮想関数テーブルをひっぱるだとか, call 命令を書くだとか, そういうコードは見当たらない.
ここまで読んでる人はあまりいないだろうけれど, 今回の話ではここが一番面白いところだったりする.
仮に EXECUTE がどんな LIR にも対応しないとして, このまま tracing を続けると何がおこるだろう. 賢明な読者諸氏は気付かれかもしれない(私は賢明でないのでだいぶ悩んだ)が, tracing 中はインタプリタも同時に動いている. これがトリックの肝になる. 先に見たとおり, インタプリタは EXECUTE を解釈して ip を書き換える. それに続く評価ループは呼び出されたメソッド(書き換えた ip)を実行する.
このとき tracing は継続したままだ. 従って呼び出したメソッドの IL も LIR に変換される. その結果, メソッドを呼び出した Fragment の LIR には, 呼び出し先メソッドの LIR が追記されていく. つまり メソッドがインライン化される.
もちろん仮想関数を素朴にインライン化するとトラブルになる. そこで trace2() の EXECUTE はガードを挟み, 呼び出すメソッドがインライン化したものと同じであることを保証している. 元と違うメソッドを呼び出そうとすると, ガードにかかってインタプリタに戻る. 参考までに guardConstant() のコードを載せておく. EXECUTE は引数 p に VM のスタックポインタを渡している. このときスタックの先頭には getforthimpl の戻り値が入っている:
void Interpreter::guardConstant(Box *p, const InterpState& state)
{
LirWriter *lirout = tracefrag->lirbuf->writer();
LInsp rt_v = uselo(p);
if (!rt_v->isconst())
{
// use guard to ensure value is const
LInsp ct_v = lirout->insImm(p->i); // p(スタックの先頭)が指す値と等しい定数を作る
LInsp cond = lirout->ins(LIR_eq, rt_v, ct_v); // 定数とスタックの比較条件を作る
guard(LIR_xf, cond, state, 0); // その条件で分岐するガードの LIR を生成する
...
}
}
つまり, こんな AS のコードから...:
public class Foo {
public function bar() : void {
doSomething();
}
}
...
foo = new Foo();
...
foo.bar();
こんなかんじのネイティブコードができると考えればいい:
// クラス定義は省略
...
Foo* foo = new (gc) Foo();
...
// 呼び出すメソッドをチェックする. vtbl は仮想関数テーブルをあらわす空想上の変数
if (Foo::vtbl.bar != foo->vtbl->bar) { goto side_exit_at_path_1; }
doSomething(); // インライン化された bar() の実装. ほんとは更にこいつもインライン化されるはず.
...
ガードを入れながらトレースするだけの至ってシンプルな仕組みで, 仮想関数がインライン化された. JIT の力を痛感する.
インライン化されれば関数をまたいだ最適化の恩恵にも与れる. また tamarin-devel での議論をみていると, 将来の改善ではガードをループの外に追い出すような高速化も目論みにあるようす. ABC のメソッドだけでなく, forth をコンパイルしてできた IL ランタイムも同様にインライン展開される.
なお Sun の Hotspot Java VM は, クラス階層を分析することでチェックのいらない仮想関数をインライン化するという. いまどき仮想関数テーブルとかいってるのは C++ だけかもしらん. あー, JIT いいなあ...
速いの?
基本的に JIT は速度のためにやるものなので, TC には TT より速くなってほしい. 外野は期待してしまうが, 先人ウォッチャーのベンチマーク によるとまだ TC より遅いらしい. これは開発中だからというせいもあるだろうし, 実のところ速度で TC に勝つのが TT の目的なのかも怪しい. 各種紹介記事 (これ とか これ) は利点として消費資源の少なさを強調している. モバイル向け VM が目的であるように見える. 部分的なコードしか JIT しないのと, アルゴリズムの単純さが省メモリに寄与するというわけ.
Sun の Hotspot Client VM はこれとは違い, 対話性を落とさないために インクリメンタルな JIT を導入するという触れ込みだった. 他にもサーバ VM を統合するなど, 色々と野心的なゴールを持っていた. "局所的な JIT" という部分だけを見ると Java hotspot VM も TT も 同じように見えてしまう. けれど, ゴールは少し違っている.
もっとも Mozilla で採用するなら性能は無視できない要素だから, 結局は性能でも TC を越える必要があるのかもしれない. 紹介を読んだ時は期待していなかったけど, インライン化をみたら急に期待が強まった. 我ながらまったく勝手なもんです.
まとめ
といわけで Tamarin Tracing の JIT のコードを読んでみた.
- Tracing Tree は CFG ではなくツリー構造ができる.
- ツリーのノード(Fragment)はループ(=前方向へのジャンプ)で終わる一連の命令列.
- Fragment のツリー構造はインタプリタの実行時に分岐をフックして漸近的に構築する.
- Fragment は通過回数を記録し, それが閾値を越えると "トレース" を開始する.
- "トレース" では LIR を命令を生成する. ループの終わりでトレースは終わる.
- トレース終了時に JIT は LIR をネイティブコードに変換する.
- ネイティブコードは Fragment に保存され, 次のループからその Fragment のパスはネイティブコードで動く.
- トレース中に通過しなかったパスへの分岐は "ガード" によって保護される.
- "ガード" がおこるとネイティブコードの実行は中断しインタプリタに戻る.
- JIT はガードのパスを "パッチ" する.
- "パッチ" ではあるパスから別の Fragment がもつネイティブコードにジャンプするよう, コードを逐次書き換える.
- ガードの仕組みを利用してメソッドはインライン化される.